Overview
Week 12 marked a pivotal experimental phase rather than linear progression. Following the Week 11 feedback to focus on noise itself rather than embodied interaction, I needed to explore new possibilities for visualizing noise's form and essence. This led to investigating generative AI as a potential tool for creating noise visualizations.
The week centered on two experimental approaches: Stable Diffusion for text-to-image generation based on noise descriptions, and Audio2Image, a specialized checkpoint model that directly analyzes audio to generate corresponding visual representations. These experiments aimed to discover whether AI-generated imagery could effectively communicate the experience and character of urban noise.
The Rationale: Why Generative AI?
Seeking New Approaches to Noise Visualization
The shift away from embodied interaction created both a challenge and an opportunity. While the project refocused on visualizing noise's essential qualities, this required finding new methods to create compelling visual representations that go beyond simple data mapping or photography.
Generative AI presented an intriguing possibility: the capacity to transform abstract sonic qualities into visual forms through machine learning models trained on vast image datasets. Rather than manually designing visualizations or relying solely on direct documentation, AI could potentially synthesize new visual languages for noise based on its analyzed characteristics.
My Background with Stable Diffusion
As someone with deep understanding of Stable Diffusion, I recognized its potential for this experimental phase. Stable Diffusion has become the most widely commercialized and universal open-source generative image model available today. My familiarity with its capabilities, limitations, and workflow made it an accessible starting point for exploring AI-assisted noise visualization.
Experiment 1: Stable Diffusion Text-to-Image Generation
The Workflow: From Sound to Text to Image
The Stable Diffusion approach involved a multi-stage translation process to convert recorded noise into visual representations:
Stage 1: Audio Analysis and Understanding
First, I carefully listened to and analyzed recorded noise samples, identifying key sonic characteristics: tonal qualities, rhythmic patterns, density, intensity, and emotional resonance. This required deep attention to the specific character of each noise environment.
Stage 2: Descriptive Translation
Next, I translated these sonic observations into detailed written descriptions. This stage involved finding language that captured not just what the noise sounded like, but what it felt like, what it evoked, and what visual metaphors might correspond to its qualities.
Stage 3: Prompt Engineering
The written descriptions were then refined into optimized prompts for Stable Diffusion. This required understanding how the model interprets language, which keywords trigger specific visual styles, and how to structure prompts for coherent results that align with the project's aesthetic goals.
Stage 4: Generation and Parameter Tuning
Finally, prompts were input into Stable Diffusion's encoder along with carefully adjusted parameters (sampling steps, CFG scale, resolution, seed values). Running the generation process, the checkpoint model interpreted the prompt and produced randomized yet highly relevant images that visualized the described noise characteristics.
Technical Process
The generation pipeline allowed for iterative refinement: testing different prompt formulations, adjusting generation parameters, and selecting outputs that best captured the essence of the original noise recordings. This human-in-the-loop approach combined AI capability with curatorial judgment.
Stable Diffusion: Process Documentation
The following images document the Stable Diffusion workflow, from launcher setup and prompt engineering to the final generated noise pollution visualizations.
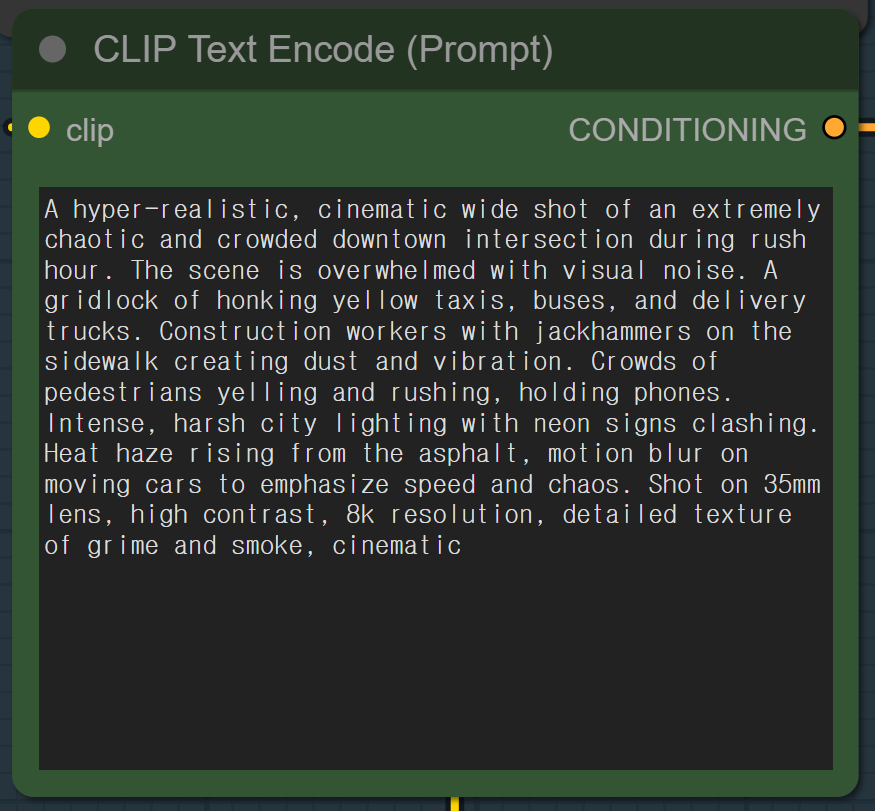
Generated Noise Visualizations
Through this process, I generated multiple images that visually interpret noise pollution. These AI-generated visualizations demonstrate how textual descriptions of sonic environments can be transformed into striking visual metaphors, maximizing visual impact while maintaining connection to the source noise.



Experiment 2: Audio2Image Direct Audio Analysis
A More Specialized Approach
While Stable Diffusion required manual translation from sound to text to image, I discovered a more specialized AI-based model: Audio2Image, an open-source checkpoint specifically designed to analyze and visualize audio directly.
This model represented a fundamentally different approach. Rather than relying on linguistic descriptions of sound, Audio2Image processes audio files directly, analyzing their acoustic properties to generate corresponding visual representations.
How Audio2Image Works (Hypothesized)
While I don't have deep technical understanding of Audio2Image's internal architecture, through experimentation I developed a working hypothesis of its process:
- Spectral Analysis: The model analyzes the audio spectrum, identifying frequency distributions, harmonic content, and spectral density
- Feature Extraction: It extracts key acoustic features including pitch range, intensity levels, bandwidth characteristics, temporal patterns, and dynamic variations
- Noise Classification: Based on these analyzed properties, the model infers the type and character of noise, categorizing it thematically (industrial, environmental, mechanical, organic, etc.)
- Visual Synthesis: Finally, it generates images that correspond to the identified noise characteristics, producing visuals that match the sonic qualities and thematic category of the source audio
This direct audio-to-image pipeline eliminates the interpretive translation step required by text-based models, potentially creating more authentic representations of the actual sonic characteristics.
Discovery and Experimentation
I discovered this open-source model while researching audio visualization techniques online. Despite limited documentation, experimentation revealed its potential for creating noise visualizations that respond directly to recorded urban soundscapes rather than textual interpretations of them.
Audio2Image: Process Documentation
The following images document the Audio2Image workflow, from launcher setup through the direct audio analysis process to the generated visual outcomes.

Generated Audio-Based Visualizations
The Audio2Image model produced visualizations that directly interpret the acoustic properties of recorded noise, creating images that respond to spectral qualities, intensity patterns, and sonic textures without human-mediated textual translation.
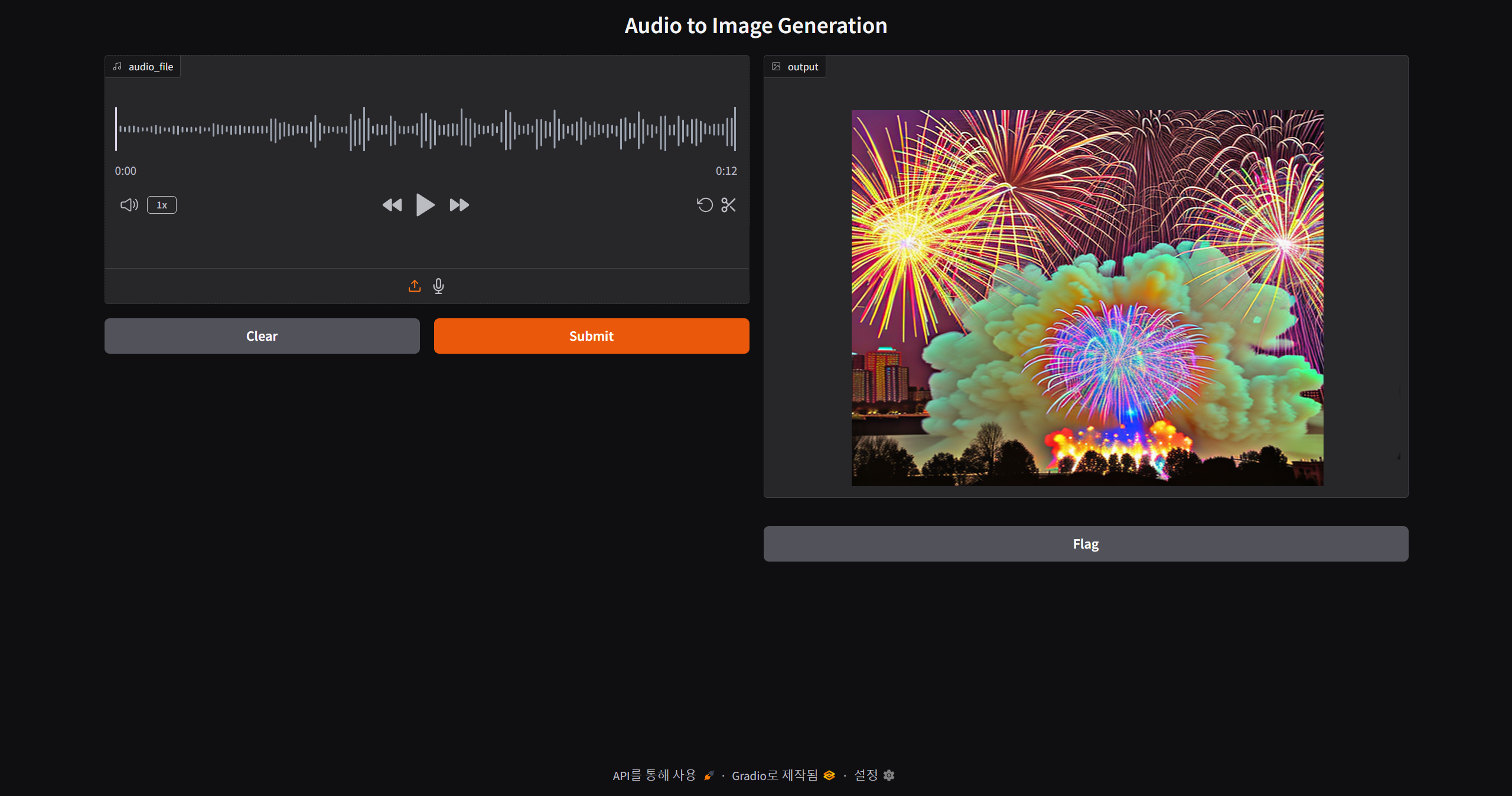
Audio2Image Output Gallery
The following images demonstrate the range of visual outputs generated by the Audio2Image model when processing different urban noise recordings. Each image represents the model's interpretation of specific acoustic characteristicsfrom construction noise to ambient urban soundscapes.










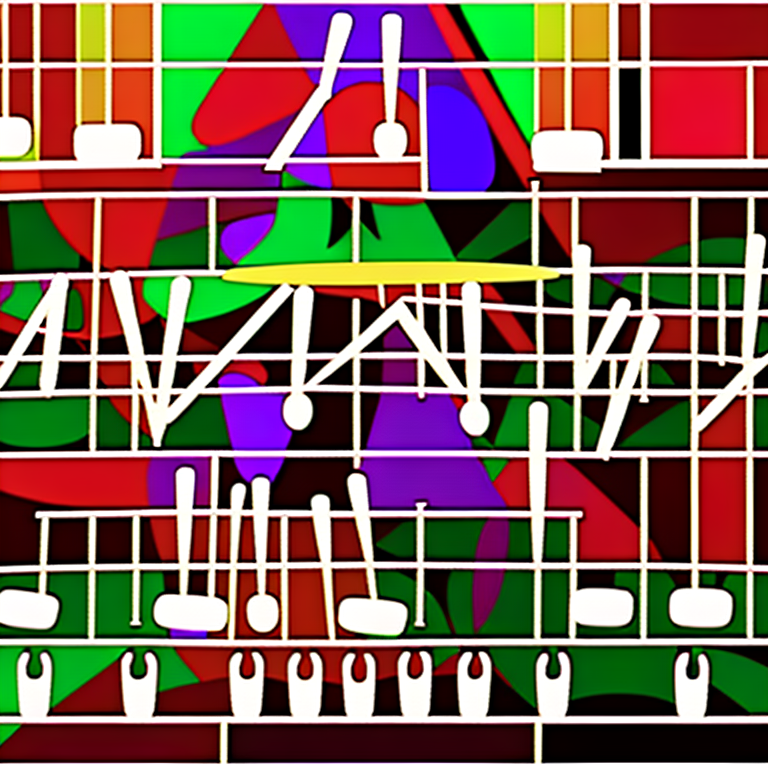
Source Audio Samples
The following are the original audio recordings used as input for the Audio2Image model. These diverse sound samples range from natural soundscapes to urban noise environments, providing the acoustic foundation for the AI-generated visualizations above.
Urban Fountain
Acoustic Soundcity
Thunder
Pianos
Firework Show
Birds at Sunrise
Alarm
Critical Reflection: Promise and Limitations
Initial Excitement: Seeing the Potential
Initially, the AI-generated visualizations felt promising. Both Stable Diffusion and Audio2Image produced visually striking images that seemed to capture something essential about noise. The images had aesthetic power, thematic coherence, and clear connection to the sonic sources that inspired them.
The ability to rapidly generate multiple visual interpretations of noise, to test different aesthetic approaches, and to create imagery that balanced abstraction with recognizability felt like a genuine breakthrough. I saw a clear path forward using generative AI as a core tool for the project.
Reconsidering: The Fundamental Limitation
However, after allowing time for reflection and deeper analysis, a fundamental limitation became apparent: these images merely depict noise rather than embody it. They are representations about noise, not transformations of noise into something more meaningful.
The problem isn't with the AI models themselves, which perform their intended functions effectively. Rather, it's a categorical issue: there exists a dimensional difference between:
- Generated imagery: Thematically and stylistically matched to noise concepts, but ultimately generic visualizations that could illustrate any similar theme
- Authentic documentation: Photographs taken on-site, recordings captured in specific locations, data collected from real environmentsmaterials that carry the actual presence and context of the noise they represent
The depth of message that authentic, site-specific documentation can communicate is literally dimensionally different from AI-generated imagery, no matter how aesthetically compelling or technically sophisticated the generation process.
The Authenticity Gap
Generative AI images lack several crucial qualities:
- Indexical Connection: They don't maintain direct causal relationship to the actual noise environments
- Contextual Specificity: They can't capture the particular qualities of specific places, times, and conditions
- Documentary Authority: They don't serve as evidence of real sonic conditions in the urban environment
- Material Presence: They don't carry the texture, grain, and imperfections of real-world documentation
- Embodied Experience: They can't convey the feeling of actually being present in noisy urban spaces
While AI can generate beautiful metaphors for noise, it cannot provide the authentic encounter with noise that the project ultimately requires to communicate its core message effectively.
Conclusion: Return to Authentic Documentation
Following this realization, I made a decisive strategic pivot: the final prototype would not use AI-generated imagery. Instead, it would be built from authentic materials gathered through direct fieldworkrecordings made on location, photographs taken in actual noise environments, and data collected from real urban spaces.
This decision prioritizes authenticity and documentary power over aesthetic convenience. While AI-generated images are easier to produce and can be infinitely varied, they cannot replace the evidentiary weight and contextual richness of materials gathered through embodied engagement with actual noise environments.
The final prototype would demonstrate that noise can be transformed into aesthetic experience not through artificial generation, but through careful curation, thoughtful presentation, and rigorous documentation of real urban soundscapes.
The Value of Experimental Detours
While the AI experiments ultimately didn't provide the path forward for the final prototype, they were far from wasted effort. This experimental detour yielded several valuable insights and capabilities.
What Was Gained
- Technical Skills: Deep familiarity with Stable Diffusion workflows and audio-analysis models that may prove useful in future projects
- Comparative Understanding: Clear recognition of the qualitative difference between generated and documented imagery, strengthening the rationale for authentic documentation
- Aesthetic Exploration: The generated images revealed possible visual languages and styles that could inform the design of authentic noise visualizations
- Process Clarity: Experimenting with AI made it clear what the project truly needs: not artificial representations, but authentic transformations of real noise
- Confidence in Direction: By testing and rejecting this approach, the decision to pursue authentic documentation became more certain and well-justified
Experimental Method as Research
This week exemplified an important research principle: sometimes the most valuable experiments are those that reveal what doesn't work, clarifying by contrast what does. The AI experiments weren't failuresthey were necessary explorations that refined the project's direction through direct testing rather than abstract speculation.
Looking Ahead: Toward the Final Prototype
With the decision made to pursue authentic documentation rather than AI-generated imagery, the path forward became clear. The remaining weeks would focus on intensive fieldwork and prototype development.
The final prototype would be built from:
- Field Recordings: High-quality audio captured across diverse urban environments in Singapore
- Site Photography: Visual documentation of the specific locations and sources generating urban noise
- Noise Data: Systematic measurements of sound intensity, frequency characteristics, and temporal patterns
- Contextual Information: Details about location, time, conditions, and sources that give meaning to the sonic data
- Curated Presentation: Thoughtful design and composition that transforms these authentic materials into compelling aesthetic experience
This approach would ground the project in reality while still achieving the core goal: demonstrating that noise, when carefully documented and artfully presented, reveals aesthetic qualities that challenge its characterization as mere pollution.
The semester's final weeks would be dedicated to gathering these materials and synthesizing them into the most compelling, coherent, and authentic prototype possibleone that honors both the conceptual ambition and the material reality of urban noise.